严谨点吧。
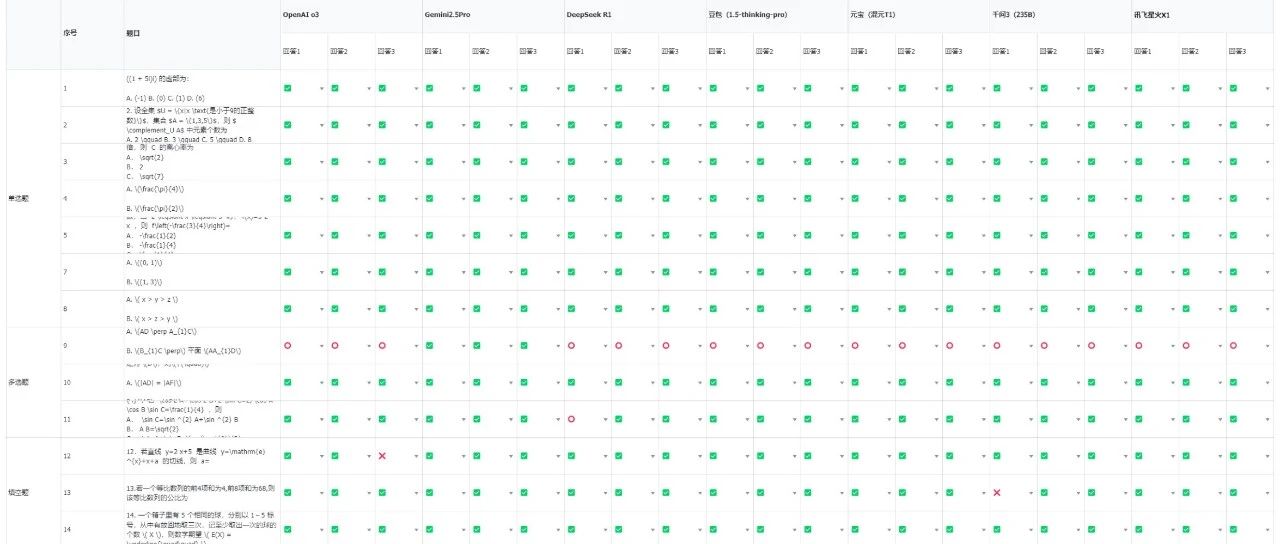
我本来真的没打算卷这个选题,因为知道大家肯定都会写,都会卷,我也想休息休息,真的就不打算写了。但是吧,用AI测语文考试还没啥,但是看了一些用AI做数学考试的文章,真的给我看的一脸地铁老头表情包,就,那个测试方法,也特么太扯淡了。结果最后得出一些不太靠谱的结论,我觉得还是蛮误导大家的。所以我觉得,我想按照我的玩法,再严谨一点的测一下大模纯数学能力型高考,给大家看一下,真实客观的评分。1. 不考解答题(因为给我标准答案我也看不懂,不知道咋给分。。)2. 所有的题目截图全部使用LaTeX编辑器转成LaTeX文本格式,再扔给大模型进行回答。LaTeX是学术界最广泛使用的数学公式排版语言,能最精确地表达数学符号,我们考的是模型的数学能力,不是考模型的多模态识图能力,比如DeepSeek根本就没多模态,用的是OCR提取文本,很可能识别错误,所以截图上传不公平,一律转化成LaTeX格式再进行统一测试。3. 剔除掉单选题第6题,因为这是单选、多选、填空题中唯一有图表的,转成文字可能会有理解歧义,同时就一题,影响不大,直接剔除。4. 单题计分方法也依照高考判分原则:单选题7道,每道5分,选项正确计分,错误不得分;多选题3道,每道6分,全对计6分,漏选按正确答案数量计分,如答案为ABCD,漏选其一扣1.5分,错选不得分;填空题3道,每道5分,填空正确计分,错误不得分。5. 每道题都会使用大模型跑3遍,根据正确比例进行分配,最大程度减少幻觉。比如OpenAI o3模型,做单选题第7题,对2次,错1次,则实际得分为5*0.66=3.3分。6. 只开推理、不使用Prompt引导、不开联网、不允许写代码在沙盒进行计算,比如o3,我直接把这几个功能关掉了。测试模型为OpenAI o3、Gemini 2.5 pro、DeepSeek R1、豆包(1.5-thinking-pro)、元宝(混元T1)、千问3(235B)、讯飞星火X1,均为推理模型。在晚上凌晨2点开始测试,因为搞API写脚本反而可能更麻烦,所以直接搞了个表格,复制粘贴测了,以至于喊了我的几个好朋友@卡尔的AI沃兹、@Max、@猫先生 一起测,硬生生测到凌晨4点。7道单选题、3道多选题、3道填空题,总分一共68分。我们得出了,我认为,非常公平客观的,每个模型的考试结果。没有收任何家钱,也没有任何利益关系,全部客观公正。第9题是个非常神奇的题目,是个多选题,只有Gemini 2.5 Pro每次都对了,其他的所有大模型,几乎全都有问题,D选项倒是全都答出来了,但是缺了B。而那个DeepSeek第11道题错的那道题,其实并不是真做错了,明明做对了,但是非要作死的瞎答,比如11题多选题,DeepSeek R1错了一道题。Gemini确实非常强,在整个逻辑上,没有一题是错的。而豆包、混元、星火位列第二梯队,在第9题上漏了一个选项,并列屈居第二。DeepSeek半对半错了一个多选题,丢了0.7分,排名第五。而Qwen3和OpenAI o3因为两个都错了1次填空题,只能被迫垫底。。通过我的测试,我相信,大家应该对于模型的数学能力,有一些了解了。高考对于现在绝大多数的推理大模型来说,其实真的就是,没有特别大的难度,跟2023年的时候,真的是天壤之别。很多测出来测的非常离谱的文章,其实最后答案错了,跟推理模型本身没有半毛钱关系,而是你把截图扔过去,各种符号啥的识别错误。比如则 \complement_{U} A,硬生生识别成了CuA。所以,折腾到现在,这场公平、客观的AI数学高考终于落幕了。其实吧,我们不睡觉,熬夜折腾这么久,想得出的并不仅仅是一个简单的分数。而是我们我们想知道,怎么才算是一场合格的AI考试。规则公正,流程严谨,技术中立,少一点博眼球的夸张,多一点对真相的执着。我始终相信,无论是对技术,还是对人生,严谨总能让我们更接近真实。以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:卡兹克
>/ 投稿或爆料,请联系邮箱:wzglyay@virxact.com


没有评论:
发表评论