GLM-5.1-HighSpeed 来了,每秒 400 token。很快的同时还很强,太顶了。。。一手测评,先来看看效果。我在 Claude Code 里面配置了 GLM-5.1 和 GLM-5.1-HighSpeed。我发了两个指令,从发出去到回复大概需要 31 秒。
继续观看
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
,
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
继续观看
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
,
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
可能也有网络的原因,Opus 4.7 大概是 47 秒。
继续观看
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
,
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
再来看 GLM-5.1-HighSpeed 的几个效果,没有快放。让 GLM-5.1-HighSpeed 生成网页,40s 搞定:
继续观看
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
,
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
继续观看
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
,
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
GLM-5.1 高速版打破行业惯例,之前大家的认知一般是尺寸小的模型才能快。
小模型的问题就是会降智。
但是 GLM-5.1 高速版背后是智谱旗舰模型 GLM-5.1,这是国产大模型第一次同时拿到顶级的智商和极致的速度。
可惜的一点是 GLM-5.1-HighSpeed 的上下文窗口还是 200K。01
效果如何?
从模型智能上,GLM-5.1 高速版完整保留 GLM-5.1 能力。
我来试几个 case,看看 GLM-5.1 高速版是什么情况。提示词:帮我生成一个3d的游戏,类似我的世界。 我能直接在网页中玩 。
继续观看
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
,
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
上面那个提示词输入后,先用 superpowers 的 brainstorming 头脑风暴了一下,和 AI 聊了几轮收敛我的需求,然后它写 Spec 文档,再写计划文档。最后拆了 10 个子任务,派 SubAgent 来逐个实现,最终完成整个 MVP 版本。如果之前用 GLM-5.1 或者 Opus 4.7 ,这一套下来,至少 1 ~2 个小时,现在只需要 11 分钟结束了。而且前置头脑风暴的追问和澄清是一个连一个,我根本反应不过来,太快了。。。。
对于我这种深度使用 Claude Code 的人,这个体验和感受太震撼了。另外我自己测了几个简单的 Case,大家可以参考,主要是对于 GLM-5.1 的,看看速度提升了,模型能力有没有变拉跨?提示词:基于桌面上的个人介绍文件, 生成一个个人介绍的网站, 风格使用 Awesome Design 里面的 Claude 的风格, 不需要头脑风暴,直接来吧.
继续观看
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
,
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
继续观看
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
,
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
体感上,确实 GLM-5.1-HighSpeed 效果稍好一些。我把它俩生成的内容,丢个 Claude Ops 4.7,让它给两个模型的输出打打分。最终结论是 GLM-5.1-HighSpeed 交付结果更好。提示词:读取桌面上的测试文件中的两个文件,一个是月报 word 模板,一个是近期用户投诉梳理表格. 请你从投诉数据中找出重复投诉,分析一下相关问题,基于 word 模板写一个月报总结.
同样的把交付的结果让 Claude Opus 4.7 来评判下。
02
为什么这么快?
GLM-5.1 高速版由智谱 GLM 团队和 TileRT 团队联合打造,在三个层面同时做了优化:
推理引擎层:针对 GLM-5.1 的架构特点重写了核心推理路径,提升单卡吞吐能力。
调度系统层:动态批处理、请求合并、KV 缓存调度优化,高并发场景下的尾延迟显著下降。
基础设施层:推理集群部署、网络链路、负载均衡的协同优化,保证 400 TPS 不是峰值数字,而是稳定的生产可用水平。
但最核心的创新在 TileRT 推理引擎本身。
模型推理速度的上限由硬件决定,但真实系统往往远未兑现这个上限。
以 8 卡 H200 服务器为例,聚合内存带宽约 38TB/s,理论上 decode 速度上限接近 1000 token/s,但实际推理服务中通常只能跑出几十 token/s。
问题出在推理框架的调度方式。
主流框架以 operator/kernel 为基本调度单元,每个算子都要走完一套完整的启动→读权重→计算→写回→同步流程。
当推理进入单 token、小 batch、多卡场景,算子被切到微秒级,原本可以忽略的调度、访存与同步开销被急剧放大。
GPU 不是没有算力,而是算力被困在了 kernel 边界之间。
operator/kernel 这一执行抽象,本身已经成为阻碍推理逼近硬件上限的结构性瓶颈。
TileRT 的做法是彻底抛弃 Runtime 层的动态调度,在编译期把整个计算图静态编排为一个常驻 GPU 的 persistent Engine Kernel。
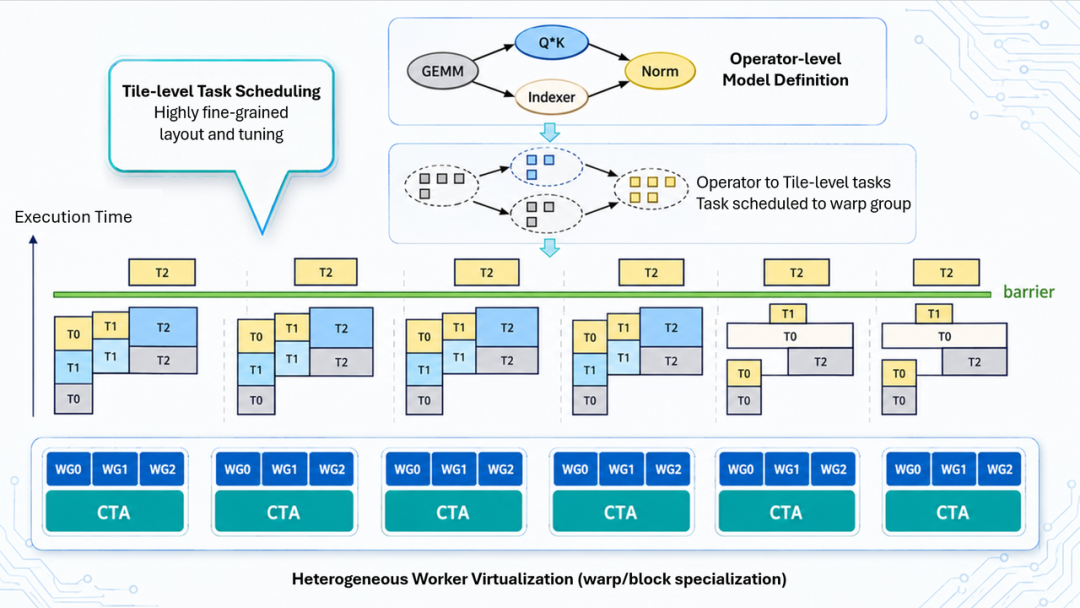
单卡之内,计算、异步 IO 与通信被拆解为 Tile 级微任务,整个推理过程只 Launch 一次,算子间的中间结果不再写回 Global Memory,而是经由 Register、Shared Memory 与 L2 Cache 直传。
多卡场景下,不同 GPU 不再执行同构逻辑,而是按计算密度与数据依赖被特化为不同 worker。
以 GLM-5.1 为例,GPU 0 专职 Sparse Indexer,GPU 1–7 承担 MLA 注意力主干,跨卡的广播、归约与残差加被压缩进同一个通信原语。
最终,推理的调度单元从 operator/kernel 降维到了 tile。
03
利好响应速度要求高的 AI 产品
比如我最近开源了一个语音优先的 Agent:Lumi,可以通过唤醒词唤醒住在你电脑的 Agent,直接语音告诉它要做啥,它做完也会语音回复你。比如我说:钱多多,请你帮我把桌面上的文件整理一下。
继续观看
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
,
刚刚, GLM-5.1 高速版来了,真的太快快快快快了。
你看,等干完活,语音播报反馈给用户:主人,我帮你整理好了。可能 5 分钟后用户早忘了这茬了。从体感上,这句任务完成的语音回复不是惊喜而是惊吓了。 突然冷不丁的冒出来一句,挺不友好的。但是如果模型推理速度超快,Agent 调用的链路足够高效的话,配合一些产品细节的打磨,这种场景的用户体验就会大幅提升的。至少从我最近 Vibe Coding 开发 Lumi 的感受上来讲,速度是影响用户体验非常重要的一环。相信后续很多对时延要求很高的 AI 产品都会选择 GLM-5.1-HighSpeed 做为底模。04
点击下方卡片,关注逛逛 GitHub
这个公众号历史发布过很多有趣的开源项目,如果你懒得翻文章一个个找,你直接关注微信公众号:逛逛 GitHub ,后台对话聊天就行了:

