最近比较忙,还就没有给大家分享干货笔记了,哈哈,今天趁周末,给你大家分享一波最近比较火的通过单一模型生
写在开头:最近决定开一个语言大模型实战系列窗口,免费分享,欢迎大家持续关注 最近比较忙,很久没有给大家分享干货笔记了,哈哈,今天趁周末,给你大家分享一波最近比较火的通过单一模型生成同步的视频和音频,最近竟然掉了一些粉丝,希望大家重新关注起来,感谢!老规矩,先看效果,再来讲解,不喜欢看细节的,直接文末获取一键包。
继续观看
一键包:LTX-2通过单一模型生成同步的视频和音频
,
一键包:LTX-2通过单一模型生成同步的视频和音频
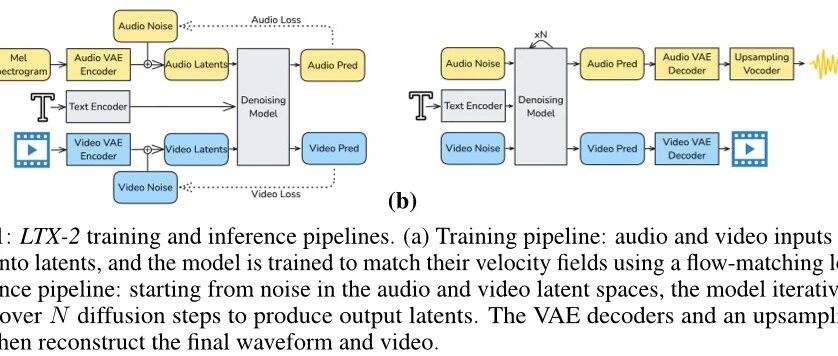
LTX-2的开源基础模型,该模型能够高效地生成高质量、同步的音频视频内容。该模型采用了双流变换器架构,其中包含一个具有14亿参数的视频流和一个具有5亿参数的音频流,并通过双向音频视频交叉注意力层进行连接,以实现跨模态共享时步长条件。此外,作者还引入了多语言文本编码器和一种新的无分类引导机制,以提高音频视觉对齐和可控性。实验结果表明,该模型在开放源代码系统中实现了最先进的音频视觉质量和提示遵从度,并且与专有模型相比,在计算成本和推理时间上都有显著优势。方法改进
与以前的模型相比,LTX-2采用了以下两个改进策略:
- 不对称的双流结构:这种结构允许每个模态根据其自己的信息密度进行独立扩展,从而更好地适应视觉和语音任务的不同需求。
- 多层特征提取器:通过提取多层中间表示的特征,LTX-2能够捕捉到更丰富的语言意义,从而提高了条件信号的质量。
此外,为了改善文本嵌入的质量,LTX-2还引入了一个文本连接器模块,该模块使用全双向注意力处理文本嵌入,并通过添加思考令牌来增强全局信息传递能力。
解决的问题
LTX-2旨在解决高质量、同步的视频和音频生成问题。它通过结合视觉和语音信息,使生成的内容更具真实感和连贯性。同时,LTX-2采用了不对称的双流结构和多层特征提取器等改进策略,以提高模型性能。
一键包基于comfyui,大家下载后一键启动,接口使用,你需要调整的地方有三个一位身穿婚纱的的美女用中文说"我要嫁给群主当老婆,不要彩礼,不要房子,不要车子"然后微笑
大模型感兴趣的可以进群交流,已在群的就不要进了,我会定时清理


没有评论:
发表评论