Nunchaku最详细部署教程,看这篇就够了!
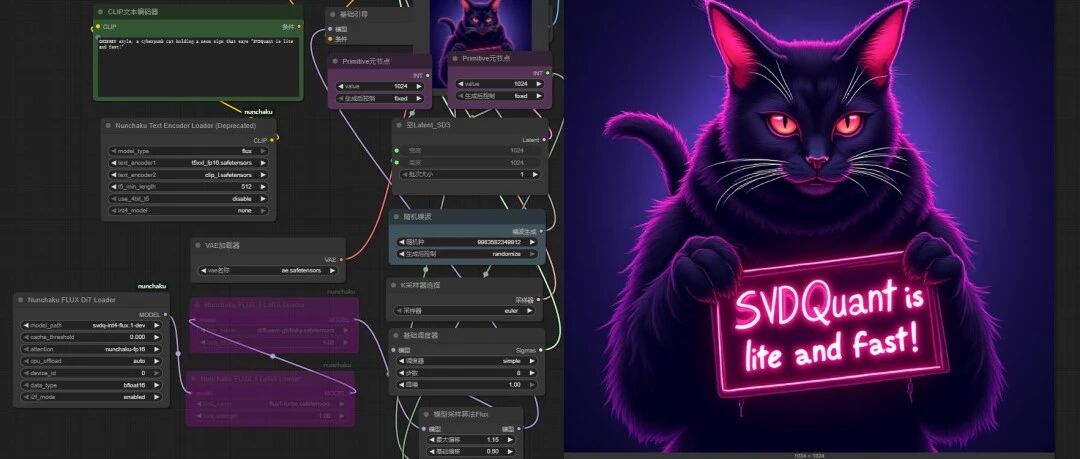
Nunchaku可以让 flux 模型8步就出图,最快时间只要3秒,而且目前已经支持支持Kontext模型。但它的安装方式比较麻烦,很多人安装老是出错,今天我出一期详细的安装部署教程,Nunchaku安装看这篇就够了!
首先,Nunchaku目前只支持NVIDIA显卡,建议先更新CUDA,CUDA的安装方法可以看这篇文章:PyTorch版本查看方法:在用秋叶启动器启运的时候,控制台可以看到PyTorch的版本号,我的版本是2.51。同时记下自己的python版本号和路径,后面要用到我的python版本号是3.11.9,路径是E:\ComfyUI-aki-v1.7\python在命令行中输入刚刚记下的python路径,后面加上" --version",按回车可以查看python版本"E:\ComfyUI-aki-v1.7\python\python.exe --version"在python路径后面加上" -m pip show torch" 可以查看torch版本"E:\ComfyUI-aki-v1.7\python\python.exe -m pip show torch"如果你的PyTorch的版本小于2.5,就需要升级了升级方法:到秋叶启动器里按下图找到Pytorch安装,选择强制重装。https://huggingface.co/mit-han-lab/nunchaku/tree/main
目前nunchaku最新版是0.3.1,我的torch版本是2.51,python版本是3.11.9,系统是windows系统,所以我要下载的版本应该是0.3.1+torch2.5-cp311-cp311-win这个版本。将下载好的文件粘贴到E:\ComfyUI-aki-v1.7\python路径下面
来到pyhon的路径:E:\ComfyUI-aki-v1.7\python\,在地址栏输入cmd,调出命令行窗口python.exe -m pip install nunchaku-0.3.1+torch2.5-cp311-cp311-win_amd64.whl
安装成功后关掉窗口即可,刚刚下载的文件可以删了。
如果已经安装了nunchaku的节点,进入nunchaku目录下的示例工作流节文件夹:
custom_nodes\ComfyUI-nunchaku\example_workflows打开第一个安装轮子工作流:install_wheel.json打开工作流后,在红框处选择通过什么方式下载轮子,如果你可以科学上网,就用huugface下载,如果不能科学上网,就选ModeScope下载。同时记得选择最新的0.31版本,然后点击运行,它就会自动下载轮子。点击运行后,它会自动根据我电脑里torch版本下载合适的轮子。从运行结果也能看出来,这个工作流自动安装的nunchaku版本是0.3.1+torch2.5-cp311-cp311-win,和我前面选择的是同一个版本。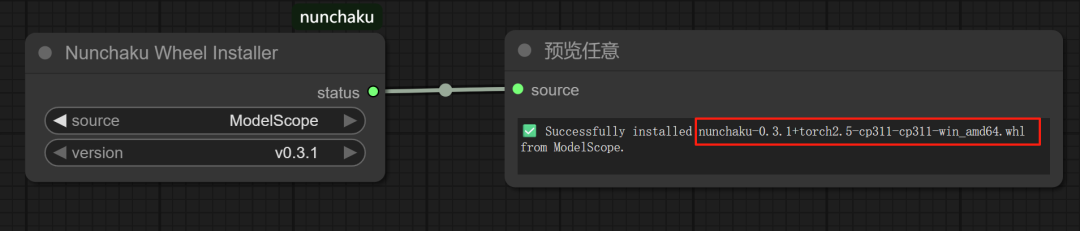
1、模型选择和模型下载
50系显卡选择nvfp4版本模型,50系以下的显卡选择int4版本模型
模型链接:
https://huggingface.co/collections/mit-han-lab/svdquant-67493c2c2e62a1fc6e93f45c
下面以svdq-int4-flux.1-dev模型为例,我们需要把该页面的所有文件全部下载下来
https://huggingface.co/mit-han-lab/svdq-int4-flux.1-dev/tree/main
ComfyUI\models\diffusion_models此时打开示例工作流:nunchaku-flux.1-dev.json工作流中默认只需要8步,我们先把本地没有的两个加速lora先给禁用掉或删掉。默认8步的出图质量还算不错,主要是速度非常快,第一次运行生图速度12.67秒,速度非常快,第二次运行速度4.29秒,更快了。目前下载下来的模型是一个文件夹,还不是一个完整的模型文件,我们可以通过官方提供的示例工作流对模型文件夹进行合并,
打开工作流:merge_safetensors.json工作流打开后选择你刚刚下载的模型版本,点击运行,它会把刚刚的模型文件夹合并为一个safetensors文件。合并完成后,就把刚刚的模型文件夹删了,以节省磁盘空间。合并完模型后,打开示例文件夹内的nunchaku-flux.1-dev.json工作流,目前Nunchaku官方还出了一 个专用的T5编码器,用它能够进一步提升生图速度,
awq-int4-flux.1-t5xxl.safetensorshttps://huggingface.co/mit-han-lab/nunchaku-t5/tree/main
模型放置路径:models\text_encoders把编码器换成专用的T5编码器后,生图竟然糊了,我们将默认步数从5提到20或更高再试一下。
不过经过我几次测试,虽然换了T5编码器后将步数提升到20后,出图速度跑进了3秒,但出的图还是有糊的。这可能是nunchaku出的编码器不太稳定造成的,期待以后再更新吧,所以我又换回了flux原生的T5编码器。目前最新版的nunchaku已经支持 kontext模型了,而且提供的是一个完整的safetensors文件,不再是一个文件夹。https://huggingface.co/mit-han-lab/nunchaku-flux.1-kontext-dev/tree/main
ComfyUI\models\diffusion_models从示例文件夹中加载工作流:nunchaku-flux.1-kontext-dev.json记得将模型换成你刚刚下载的模型
生图速度也明显提升了,第一次生图时间32.21秒,第二次只有20秒,比正常出图速度明显提升。nunchaku确实可以数倍提升生图速度,但模型的质量可能比flux官方模型还差点意思,如果只求速度不在乎质量有瑕疵可以用它。用同样的提示词,下面左图为nunchaku出的图,右图为 flux 官方模型出的图,可以看出nunchaku的出图质量还是差点意思的。不过第二次出图时,nunchaku9.86秒,flux官模29.29秒,速度提升了3倍!另外nunchaku提供的 T5编码器好像不太稳定,不建议使用。目前nunchaku还提供了很多很多其他功能的官方工作流(需要下载相应的模型),大家有兴趣可以自己去试一下。unchaku-flux.1-kontext-dev:
https://www.runninghub.cn/post/1942473442157342721https://www.runninghub.cn/post/1942467291403464705
感谢您的阅读,麻烦点个赞+在看吧!
没有评论:
发表评论